This document describes the module for frequency, attestation and corpus information of the Lexicon Model for Ontologies (lemon) as a result of the work of the Ontology Lexica community group (OntoLex). The module is targeted at complementing dictionaries and other linguistic resources containing lexicographic data with a vocabulary to express
corpus-derived statistics (frequency and cooccurrence information, collocations),
pointers from lexical resources to corpora and other collections of text (attestations),
the annotation of corpora and other language resources with lexical information (lemmatization against a dictionary), and
distributional semantics (collocation vectors, word embeddings, sense embeddings, concept embeddings).
The module tackles use cases in corpus-based lexicography, corpus linguistics and natural language processing, and operates in combination with the lemon core module, referred to as OntoLex, as well as with other lemon modules.
This document is a working draft for a module for frequency, attestation and corpus data of the OntoLex specifications.
It is not a W3C Standard nor is it on the W3C Standards Track.
There are a number of ways that one may participate in the development of this report:
More information about meetings of the ONTOLEX group can be obtained
here
Source code
for this document can be found on Github.
Disclaimer: This draft follows closely the structure and design of The Ontolex Lexicography Module. Draft Community Group Report 28 October 2018, edited by Julia Bosque-Gil and Jorge Gracia. In particular, motivational and introductory text are partially adapted without being marked as quotes. This is to be replaced by original text before publication.
Introduction
Background and Motivation
The lemon model provides a core vocabulary (OntoLex) to represent linguistic information associated to ontology and vocabulary elements. The model follows the principle of semantics by reference in the sense that the semantics of a lexical entry is expressed by reference to an individual, class or property defined in an ontology.
The current version of lemon (as an outcome of the OntoLex group, sometimes referred as OntoLex-lemon in the literature) as well as its previous version (lemon [1]) have been increasingly used in the context of dictionaries and lexicographical data to convert existent lexicographic information into the standards and formats of the Semantic Web. In consequence, a designated lemonmodule for lexicography (lexicog) has been designed, with applications in monolingual [2], bilingual [3], and multilingual [4] dictionaries, as well as diachronic [5], dialectal [6], and etymological ones [7], among others.
This module is partially motivated by requirements of corpus-based lexicography (frequency and collocation information) and digital philology (linking lexical resources with corpus data).
A second motivation for a lemon model for corpus-based information comes from natural language processing. With the rise of distributional semantics since the early 1990s, lexical semantics have been complemented by corpus-based co-occurrence statistics (KEYNESS-REFERENCE???), collocation vectors (Schütze 1993), word embeddings (Collobert et al. 2012) and sense embeddings (??? and Schütze, 2017). With the proposed module, lemon can serve as a community standard to encode, store and exchange vector representations (embeddings) along with the lexical concepts, senses, lemmas or words that they represent. The processing of word embeddings is beyond the scope of this module. Embeddings are thus represented as literals ("BLOB").
The added value of using linked data technologies to represent such information is an increased level of interoperability and integration between different types of lexical resources, the textual data they pertain to, as well as distributional representations of words, lexical senses and lexical concepts. Creating a lemon module in the OntoLex CG is a suitable means for establishing a vocabulary on a broad consensus that takes into account all use cases identified above in an adequate fashion.
The OntoLex community is the natural forum to accomplish this for several reasons:
The extended use of lemon to support digital lexicography,
the improved application and applicabiltiy of lemon in natural language processing,
the coming together of the lexicography, AI and human language technology communities, resp. resources, and
the possibility of reusing already available mechanisms in lemon, preventing researchers from "re-inventing the wheel",
Aim and Scope
The goal of this module is to complement lemon core elements with a vocabulary layer to represent lexicographical and semantic information derived from or defined with reference to corpora and external resources in a way that (a) generalizes over use cases from digital lexicography, natural language processing, artificial intelligence, computational philology and corpus linguistics, that (b) facilitates exchange, storage and re-usability of such data along with lexical information,
and that (c) minimizes information loss.
The scope of the model is three-fold:
extending the OntoLex-lexicog model with corpus information to support existing challenges in corpus-driven lexicography,
modelling existing lexical and distributional-semantic resources (corpus-based dictionaries, collocation dictionaries, embeddings) as linked data, to allow their conjoint publication and inter-operation by Semantic Web standards, and
providing a conceptual / abstract model of relevant concepts in distributional semantics that facilitates building linked data-based applications that consume and combine both lexical and distributional information.
Corpus as used throughout this document is understood in its traditional, broader sense as a structured data collection -- or material suitable for being included into such a collection, such as manuscripts or other works.
We do not intend to limit the use of the term to corpora in a linguistic or NLP sense. Language resources of any kind (web documents, dictionaries, plain text, unannotated corpora, etc.) are considered "corpus data" and a collection of such information as a "corpus" in this sense. Any information drawn from or pertaining to such information is considered "corpus-based".
Namespaces
This is a list of relevant namespaces that will be used in the rest of this document:
OntoLex module for frequency, attestation and corpus information
We consider all lemon core concepts as being countable, annotatable/attestable and suitable for a numerical representation by means of a vector (embedding). For this reason, we define the rdfs:domain of all properties that link lexical and corpus information by means of ontolex:Element, an abstract superclass of
ontolex:Form (for word frequency and plain word/phrase embeddings),
ontolex:LexicalEntry (for lemma frequency and lemma-based word/phrase embeddings),
ontolex:LexicalSense (for sense frequency and sense embeddings), and
ontolex:LexicalConcept (for concept frequency and concept embeddings).
ontolex:Element as a superclass of ontolex:LexicalEntry, ontolex:Form, ontolex:LexicalSense and ontolex:LexicalConcept
Such a top-level concept used to exist in Monnet-lemon, but has been abandoned in the 2016 edition of lemon.
If this concept is not provided by a future revision of the lemon core vocabulary, it will be introduced by this module.
Note that the introduction of ontolex:Element has no effect on lemon core other that facilitating vocabulary organization, as ontolex:Element is not to be used for data modeling.
Overview
The following diagram depicts the OntoLex module for frequency, attestation and corpus information (fraq). Boxes represent classes of the model. Arrows with filled heads represent object properties. Arrows with empty heads represent rdfs:subClassOf.
Vocabulary elements introduced by this module are shaded grey (classes) or set in italics.
Module for Frequency, Attestation and Corpus Information (frac), overview
DISCUSSION:
Looks more complicated than it is. Shall we drop inferrable information ? (rdf:rest, rdf:first are available vocabulary elements because ContextualRelation is a subclass of rdf:List, subclasses of ontolex:Element should be dropped once ontolex:Element is introduced.)
Keep rdf:List elements only if preserved in other ontolex modules.
Definitions
Frequency
Frequency information is a crucial component in human language technology. Corpus-based lexicography originates with Francis and Kucera (1958), and subsequently, the analysis of frequency distributions of word forms, lemmas and other linguistic elements has become a standard technique in lexicography and philology, and given rise to the field of corpus linguistics.
At its core, this means that lexicographers use corpus frequency and distribution information while compiling lexical entries (also see the section on collocations and similarity below).
As a qualitative assessment, frequency can be expressed with lexinfo:frequency, "[t]he relative commonness with which a term occurs". However, this is an object property with possible values lexinfo:commonlyUsed, lexinfo:infrequentlyUsed, lexinfo:rarelyUsed, while absolute counts over a particular resource (corpus) require novel vocabulary elements.
Absolute frequencies are used in computational lexicography (e.g., the Electronic Penn Sumerian Dictionary), and they are an essential piece of information for NLP and corpus linguistics.
In order to avoid confusion with lexinfo:Frequency, this is defined with reference to a particular dataset, a corpus.
Corpus frequency provides the absolute number of attestations (rdf:value) of a particular ontolex:Element (see frac:frequency) in a particular language resource (dct:source).
SubClassOf: rdf:value exactly 1 xsd:int, dct:source min 1
If information from multiple language resources is aggregated (also cf. the section on embeddings below), multiple dct:source statements should be provided, to each resource individually. The cardinality of dct:source is thus 1 or higher.
QUESTION: better alternative to dct:source?
The following example illustrates word and form frequencies for the Sumerian word a (n.) "water" from the Electronic Penn Sumerian Dictionary and the frequencies of the underlying corpus.
# word frequency, over all form variants
epsd:a_water_n a ontolex:LexicalEntry;
frac:frequency [
a frac:CorpusFrequency;
rdf:value "4683"^^xsd:int;
dct:source <http://oracc.museum.upenn.edu/epsd2/pager> ] .
# form frequency for individual orthographical variants
epsd:a_water_n ontolex:canonicalForm [
ontolex:writtenRep "𒀀"@sux-Xsux, "a"@sux-Latn;
frac:frequency [
a frac:CorpusFrequency;
rdf:value "4656"^^xsd:int;
dct:source <http://oracc.museum.upenn.edu/epsd2/pager> ] ] .
epsd:a_water_n ontolex:otherForm [
ontolex:writtenRep "𒀉"@sux-Xsux, "a2"@sux-Latn;
frac:frequency [
a frac:CorpusFrequency;
rdf:value "1"^^xsd:int;
dct:source <http://oracc.museum.upenn.edu/epsd2/pager> ] ] .
epsd:a_water_n ontolex:otherForm [
ontolex:writtenRep "𒂊"@sux-Xsux, "e"@sux-Latn;
frac:frequency [
a frac:CorpusFrequency;
rdf:value "24"^^xsd:int;
dct:source <http://oracc.museum.upenn.edu/epsd2/pager> ] ].
The example shows orthographic variation (in the original writing system, Sumerian Cuneiform sux-Xsux, and its Latin transcription sux-Latn). It is slightly simplified insofar as the ePSD2 provides individual counts for different periods and that only three of six orthographical variants are given. Note that these are orthographical variants, not morphological variants (which are not given in the dictionary).
It is necessary to provide the link to the underlying corpus for every frequency assessment because the same element may receive different counts over different corpora. For data modelling, it is recommended to define a corpus- or collection-specific subclass of frac:CorpusFrequency with a fixed dct:source value. This leads to more compact data and avoids potential difficulties with the Open World Assumption (interpretability of incomplete data).
# Corpus Frequency in the EPSD corpus
:EPSDFrequency rdfs:subClassOf frac:CorpusFrequency.
:EPSDFrequency rdfs:subClassOf
[ a owl:Restriction ;
owl:onProperty dct:source ;
owl:hasValue <http://oracc.museum.upenn.edu/epsd2/pager> ] .
# frequency assessment
epsd:a_water_n frac:frequency [
a :EPSDFrequency;
rdf:value "4683"^^xsd:int ].
frac:CorpusFrequency can be extended with additional filter conditions to define sub-corpora. For example, we can restrict the subcorpus to a particular time period, e.g., the Neo-Sumerian Ur III period:
# EPSD frequency for the Ur-III period (aat:300019910)
:EPSDFrequency_UrIII
rdfs:subClassOf :EPSDFrequency;
rdfs:subClassOf
[ a owl:Restriction ;
owl:onProperty dct:temporal ;
owl:hasValue aat:300019910 ] .
# frequency assessment for sub-corpus
epsd:a_water_n frac:frequency [
a :EPSDFrequency_UrIII;
rdf:value "2299"^^xsd:int ].
Attestation
This is an attempt for a consensus model based on Depuydt and de Does (2018) and Khan and Boschetti (2018). We do focus on data structures, the following aspects are not covered: Datatype properties regarding confidence (assumed to be in lexinfo), bibliographical details (subject to other vocabularies), and details of resource linking (subject to other vocabularies).
Attestation module following Depuydt and de Does (2018)Attestation module following Khan and Boschetti (2018)
"Lexicographers use examples to support their analysis of the headword. The examples can either be
authentic (exact quotations), adapted (modified versions of authentic examples) or invented examples.
Authentic examples are attributed quotations (citations), which not only elucidate
meaning and illustrate features of the headword (spelling, syntax, collocation, register etc.), but also
function as attestations and are used provide evidence of the existence of a headword.
We therefore call these examples “attestations”." (Depuydt and de Does 2018)
An Attestation is normally an exact or normalized quotation or excerpt from a source document that illustrates a particular form, sense or lexeme in authentic data.
Attestations should be accompanied by a Citation or the URI of a digital edition of the respective locus (dct:source). This URI can be externally defined (e.g., as a oa:Annotation or as a NIF URI), and can refer either to the entire work or to the exact location of the attestation within this source.
A Citation is a bibliographical reference to a source for the definition or illustration of a particular sense, form or lexeme. A citation can provide an attestation, but can also stand on its own.
Details of bibliographical references are beyond the scope of the current proposal. Several designated vocabularies exist, e.g., FaBiO and CiTO,
Bibo,
the Open Citation Corpus,
SpringerNature SciGraph
BiRO or C4O
The property makeAttestation assigns a particular Citation a frac:Attestation.
rdfs:range frac:Citation
rdfs:domain frac:Attestation
CC: Naming follows K and B, I'm not too happy with the name, though, because it's too close to attestation, it will likely be confused.
Embeddings
In distributional semantics, the contexts in which a word is attested are taken to define its meaning. Contextual similarity is thus a correlate of semantic similarity. Different representations of context are possible, the most prominent model to date is the form of a vector.
A word vector can be created, for example, by means of a reference list of vocabulary items, where every reference word is associated with a fixed position, e.g., ship with position 1, ocean with 2, sky with 3, etc.
Given a corpus (and a selection criterion for collocates, e.g., within the same sentence), every word in the corpus can be described by the frequency that a reference word occurred as a collocate in the corpus.
Assume we want to define the meaning of frak, with (exactly) the following attestations in our sample corpus (random samples from wikiquote):
It's in the frakking ship!
Have you lost your frakkin' mind?
Oh, for frak's sake, let me see if I can make heads or tails of it.
It's a frakking Cylon.
Our job isn't to be careful, it's to shoot Cylons out of the frakking sky!
With the following list of reference words: (ship, ocean, lose, find, brain, mind, head, sky, Cylon, ...), we obtain the vector (1,0,1,0,0,1,1,1,2,...) for the lemma (lexical entry) frak. For practical applications, these vectors are projected into lower-dimensional spaces, e.g., by means of statistical (Schütze 1993) or neural methods (Socher et al. 2011).
The process of mapping a word to a numerical vector and its result are referred to as "word embedding". Aside from collocation counts, other methods for creating word embeddings do exist, but they are always defined relative to a corpus.
Embeddings have become a dominating paradigm in natural language processing and machine learning, but, if compiled from large corpora, they require long training periods and thus tend to be re-used.
However, embedding distributions often use tool-specific binary formats (cf. Gensim), and thus a portability problem arises.
CSV and related formats (cf. SENNA embeddings) are a better alternative, but their application to sense and concept embeddings (as provided, for example, by Rothe and Schütze 2017)
is problematic if their distribution is detached from the definition of the underlying sense and concept definitions.
With frac, Ontolex-lemon provides a vocabulary for the conjoint publication and sharing of embeddings and lexical information at all levels: non-lemmatized words (ontolex:Form), lemmatized words (ontolex:LexicalEntry), phrases (ontolex:MultiWordExpression), lexical senses (ontolex:LexicalSense) and lexical concepts (ontolex:LexicalConcept).
We focus on publishing and sharing embeddings, not on their processing by means of Semantic Web formalisms, and thus, embeddings are represented as untyped or string literals with whitespace-separated numbers. If necessary, more elaborate representations, e.g., using rdf:List, may subsequently be generated from these literals.
Lexicalized embeddings provide their data via rdf:value, and should be published together with their metadata, most importantly
procedure/method (dct:description with free text, e.g., "CBOW", "SKIP-GRAM", "collocation counts")
An Embedding provides a numerical vector (the string of rdf:value) for a given ontolex:Element (see frac:embedding). It is defined by the methodology used for creating it (dct:description), the URI of the corpus or language resource from which it was created (dct:source), and its dimensionality (length of the vector, dct:extent).
SubClassOf: rdf:value exactly 1 xsd:string, dct:source min 1, dct:description min 1
Question: Rename "Embedding" (the concept, not the property) to "Vector" ?
For embeddings, we recommend using whitespace-separated numbers as their rdf:value. In particular, commas as separators are discouraged because they might be confused with the decimal point, depending on the locale of the user. We recommend the following regular expression for parsing embedding values (example in Perl):
split(/[^0-9\.,\-]+/, $value)
This means that doubles should be provided in the conventional format, not using the exponent notation.
The 50-dimensional
GloVe 6B (Wikipedia 2014+Gigaword 5) embedding for frak is given below:
As a lemma (LexicalEntry) embedding, this can be represented as follows:
:frak a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "frak"@en;
frac:embedding [
a frac:Embedding;
rdf:value "0.015246 -0.30472 0.68107 ...";
dct:source
<http://dumps.wikimedia.org/enwiki/20140102/>,
<https://catalog.ldc.upenn.edu/LDC2011T07>;
dct:extent 50^^^xsd:int;
dct:description "GloVe v.1.1, documented in Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation, see https://nlp.stanford.edu/projects/glove/; uncased"@en. ].
As with frac:Frequency, we recommend defining resource-specific subclasses of frac:Embedding in order to reduce redundancy in the data:
# resource-specific embedding class
:GloVe6BEmbedding_50d rdfs:subClassOf frac:Embedding;
rdfs:subClassOf
[ a owl:Restriction;
owl:onProperty dct:source;
owl:hasValue
<http://dumps.wikimedia.org/enwiki/20140102/>,
<https://catalog.ldc.upenn.edu/LDC2011T07> ],
[ a owl:Restriction;
owl:onProperty dct:extent;
owl:hasValue 50^^^xsd:int ],
[ a owl:Restriction;
owl:onProperty dct:description;
owl:hasValue "GloVe v.1.1, documented in Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation, see https://nlp.stanford.edu/projects/glove/; uncased"@en. ].
# embedding assignment
:frak a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "frak"@en;
frac:embedding [
a :GloVe6BEmbedding_50d;
rdf:value "0.015246 -0.30472 0.68107 ..." ].
Examples for non-word embeddings:
AutoExtend: (a method to build) synset and lexeme embeddings, data here
Vec2Synset: (a method to build) WordNet synset (= LexicalConcept) embeddings
Character embeddings are probably beyond the scope of OntoLex, unless characters are regarded LexicalEntries. (Which they could, for languages such as Chinese or Sumerian certainly, but also for Western languages -- given the fact that character-level pseudo entries are sometimes used in dictionaries to describe the phonology and orthography of a language. This is the case, for example, for Grimm's Deutsches Wörterbuch.)
Collocations
CC: this is a part I am less certain about, mostly because of the rdf:List modelling (which is inspired by lexicog). Alternative suggestions welcome.
Collocation analysis is an important tool for lexicographical research and instrumental for modern NLP techniques. It has been the mainstay of 1990s corpus linguistics and continues to be an area of active research in computational philology. ... (MORE MOTIVATION AND EXAMPLES)
Collocations are usually defined on surface-oriented criteria, i.e., as a relation between forms or lemmas (lexical entries), not between senses, but they can be analyzed on the level of word senses (the sense that gave rise to the idiom or collocation). Indeed, collocations often contain a variable part, which can be represented by a ontolex:LexicalConcept.
Collocations can involve two or more words, they are thus modelled as an rdf:List of ontolex:Elements.
Collocations may have a fixed or a variable word order. By default, we assume variable word order, where a fixed word order is required, the collocation must be assigned lexinfo:termType lexinfo:idiom.
Collocations obtained by quantitative methods are characterized by their method of creation (dct:description), their collocation strength (rdf:value), and the corpus used to create them (dct:source). Collocations share these characteristics with other types of contextual relations (see below), and thus, these are inherited from the abstract frac:ContextualRelation class.
ContextualRelation provides a relation between two or more lexical elements, characterized by a dct:description of the nature of relation, a corpus (dct:source) from which this relation was inferred, and a weight or probability assessment (rdf:value).
SubClassOf: rdf:List; rdf:value exactly 1 xsd:double, dct:source min 1, dct:description min 1 xsd:string
We distinguish two primary contextual relations: syntagmatic (between co-occurring elements) and paradigmatic (between elements that can be substituted for each other). Syntagmatic contextual relations are formalized with frac:Collocation.
A Collocation is a frac:ContextualRelation that holds between two or more ontolex:Elements based on their co-occurrence within the same utterance and characterized by their collocation weight (rdf:value) in one or multiple source corpora (dct:source).
SubClassOf:frac:ContextualRelation
rdf:first: only ontolex:Element
rdf:rest*/rdf:first: only ontolex:Element
Collocations are lists of ontolex:Elements, and formalized as rdf:List. Collocation elements can thus be directly accessed by rdf:first, rdf:_1, rdf:_2, etc. The property rdf:rest returns a rdf:List of ontolex:Elements, but not a frac:Collocation.
By default, frac:Collocation is insensitive to word order. If a collocation is word order sensitive, it should be characterized by an appropriate dct:description, as well as by having lexinfo:termType lexinfo:idiom.
lexinfo:idiom is ``[a] group of words in a fixed order that have a particular meaning that is different from the meanings of each word understood on its own.'' In application to automatically generated collocations, the criterion of having `a particular meaning' is necessarily replaced by `a particular distribution pattern', as reflected by the collocation weight (rdf:value). Idioms in the narrower sense of lexicalized multi-word expressions should not be modelled as frac:Collocations, but as ontolex:MultiWordExpressions.
[TO BE DISCUSSED]
The most elementary level of a collocation is an n-gram, as provided, for example, by Google Books, which provide n-gram frequencies per publication year as tab-separated values. For 2008, the 2012 edition provides the following statistics for the bigram kill + switch.
In this example, forms are string values (cf. ontolex:LexicalForm), lexemes are string values with parts-of-speech (cf. ontolex:LexicalEntry). A partial ontolex-frac representation is given below:
# kill (verb)
:kill_v a ontolex:LexicalEntry;
lexinfo:partOfSpeech lexinfo:verb;
ontolex:canonicalForm :kill_cf.
# kill (canonical form)
:kill_cf ontolex:writtenRep "kill"@en.
# switch (noun)
:switch_n a ontolex:LexicalEntry;
lexinfo:partOfSpeech lexinfo:noun;
ontolex:canonicalForm :switch_cf.
# switch (canonical form)
:switch_cf ontolex:writtenRep "switch"@en.
# form-form bigrams
(:kill_cf :switch_cf) a frac:Collocation;
rdf:value "199";
dct:description "2-grams, English Version 20120701, word frequency";
dct:source <https://books.google.com/ngrams>;
dct:temporal "2008"^^xsd:date;
lexinfo:termType lexinfo:idiom.
(:kill_cf :switch_cf) a frac:Collocation;
rdf:value "121";
dct:description "2-grams, English Version 20120701, document frequency";
dct:source <https://books.google.com/ngrams>;
dct:temporal "2008"^^xsd:date;
lexinfo:termType lexinfo:idiom.
# form-lexeme bigrams
(:kill_cf :switch_n) a frac:Collocation;
rdf:value "187";
dct:description "2-grams, English Version 20120701, word frequency";
dct:source <https://books.google.com/ngrams>;
dct:temporal "2008"^^xsd:date;
lexinfo:termType lexinfo:idiom.
(:kill_cf :switch_n) a frac:Collocation;
rdf:value "115";
dct:description "2-grams, English Version 20120701, document frequency";
dct:source <https://books.google.com/ngrams>;
dct:temporal "2008"^^xsd:date;
lexinfo:termType lexinfo:idiom.
Question: can canonical forms be shared across different lexical entries? For the case of plain word n-grams, this is presupposed here.
The second example illustrates more complex types of collocation are provided as provided by the Wortschatz portal (scores and definitions as provided for beans, spill the beans, etc.
@prefix wsen: <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012&word=>
# selected lexical entries
# (we assume that every Wortschatz word is an independent lexical entry)
wsen:beans a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "beans"@en.
wsen:spill a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "spill"@en.
wsen:green a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "green"@en.
wsen:about a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "about"@en
# collocations, non-lexicalized
(wsen:spill wsen:beans) a frac:Collocation;
rdf:value "182";
dct:description "cooccurrences in the same sentence, unordered";
dct:source <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.
(wsen:green wsen:beans) a frac:Collocation;
rdf:value "778";
dct:description "left neighbor cooccurrence";
dct:source <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
(wsen:beans wsen:about) a frac:Collocation;
rdf:value "35";
dct:description "right neighbor cooccurrence";
dct:source <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
# multi-word expression, lexicalized (!)
wsen:spill+the+beans a ontolex:MultiWordExpression;
ontolex:canonicalForm/ontolex:writtenRep "spill the beans"@en.
(wsen:beans wsen:spill+the+beans) a frac:Collocation;
rdf:value "401";
dct:description "cooccurrences in the same sentence, unordered";
dct:source <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.
Again, it is recommended to define resource-specific subclasses of frac:Collocation with default values for dct:description, dct:source, and (where applicable) lexinfo:termType.
Similarity
Similarity is a paradigmatic contextual relation between elements that can replace each other in the same context. In distributional semantics, a quantitative assessment of the similarity of two forms, lexemes, phrases, word senses or concepts is thus grounded in numerical representations of their respective contexts, i.e., their embeddings.
In a broader sense of `embedding', also bags of words fall under the scope of frac:Embedding, see the usage note below.
Similarity is characterized by a similarity score (rdf:value), e.g., the number of shared dimensions/collocates (in a bag-of-word model) or the cosine distance between two word vectors (for fixed-size embeddings), the corpora which we used to generate this score (dct:source), and the method used for calculating the score (dct:description).
Similarity is symmetric. The order of similes is irrelevant.
Like frac:Collocation, quantitative similarity relations are modelled as a subclass of frac:ContextualRelation (and thus, as an rdf:List).
Similarity is a frac:ContextualRelation that holds between two or more frac:Embeddings, and is characterized by a similarity score (rdf:value) in one or multiple source corpora (dct:source) and a dct:description that explains the method of comparison.
SubClassOf:frac:ContextualRelation
rdf:first: only frac:Embedding
rdf:rest*/rdf:first: only frac:Embedding
frac:Similarity applies to two different use cases: The specific similarity between (exactly) two words, and similarity clusters (synonym groups obtained from clustering quantitatively obtained synonym candidates according to their distributional semantics in a particular corpus) that can contain an arbitrary number of words.
Both differ in the semantics of rdf:value:
Quantitatively obtained similarity relations normally provide a different score for every pair of similes.
Within a similarity cluster, a generalization over these pair-wise scores must be provided.
This could be the minimal similarity between all cluster members or a score produced by the clustering algorithm (e.g., depth or size of cluster).
This must be explained in dct:description.
Similarity is defined as a property of embeddings, not between ontolex:Elements.
This excludes at least two important use cases:
manual similarity assessments as used for evaluating similarity assessments, and as created, for example, as part of psycholinguistic association or priming experiments (also cf. WordNet synsets, which provide, however, detailed lexicographic information in addition to similarity, and which thus to be represented as ontolex:LexicalConcept),
similarity assessments obtained by other means than embeddings, e.g., by means of a traditional bag of words.
In both (and similar) cases, the recommendation is to make use of (a resource-specific subclass of) frac:Embedding, nevertheless, and to document the specifics of the similarity relation and/or the embeddings in the dct:description of these embeddings. For the first use case, this approach can be justified by assuming that embeddings are correlated with a psycholinguistically `real' phenomenon. For the second use case, any bag of words can be interpreted as an infinite-size binary vector for which an embedding provides a fixed-size approximation.
As with frequency and embeddings, a resource-specific similarity type can be defined, analoguously. In particular, this is required if directed (asymmetric) similarity assessments are to be provided.
Corpus Annotation (non-normative)
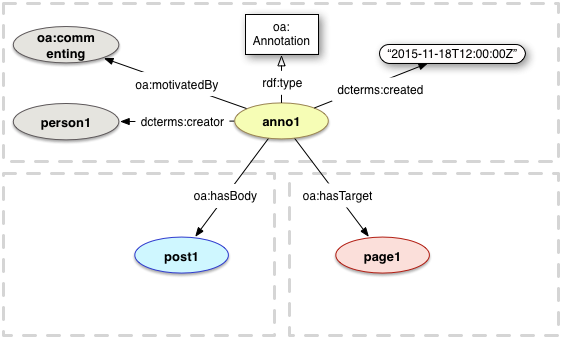
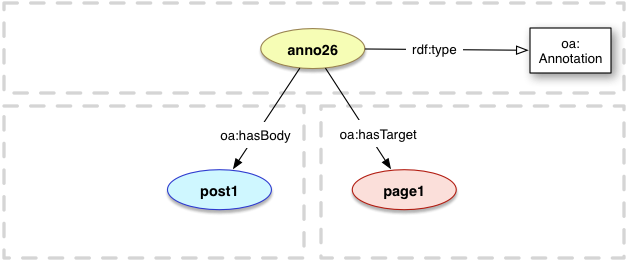
The Ontolex Module for Frequency, Attestation and Corpus Information does not specify a vocabulary for annotating corpora or other data with lexical information, as this is being provided by the Web Annotation Vocabulary. The following description is non-normative as Web Annotation is defined in a separate W3C recommendation. The definitions below are reproduced, and refined only insofar as domain and range declarations have been refined to our usecase.
In Web Annotation terminology, the annotated element is the `target', the content of the annotation is the `body', and the process and provenance of the annotation is expressed by properties of oa:Annotation.
The relationship between an Annotation and its Target.
Domain: oa:Annotation
The Web Annotation Vocabulary supports different ways to define targets. This includes:
plain URI: The target can be a URI defined within the corpus (e.g., if corpus data is provided as native RDF, or by means of the @about attribute in an HTML/XML+RDFa document, or by means of @xml:id in a TEI/XML document).
string URI: String URIs provide the possibility to point directly to a text fragment in a web document, using the URI schemas as provided by RFC5147 (text files only) or NIF (all text-based formats).
oa:TextPositionSelector: a range of text defined by the start and end positions of the selection in the stream
oa:DataPositionSelector: a range of data by recording the start and end positions of the selection in the stream
oa:TextQuoteSelector: The TextQuoteSelector describes a range of text by copying it. The TextQuoteSelector can include some of the text immediately before (a prefix) and after (a suffix) it to distinguish between multiple copies of the same sequence of characters. If this does suffice for disambiguation, all matching text fragments in the document are being annotated.
oa:XPathSelector: select elements and content within a resource that supports the Document Object Model via a specified XPath value.
oa:RangeSelector: identify the beginning and the end of the selection by using other Selectors.
oa:Annotation explicitly allows n:m relations between ontolex:Elements and elements in the annotated elements. It is thus sufficient for every ontolex:Element to appear in one oa:hasBody statement in order to produce a full annotation of the corpus.
As for frequency, embeddings, etc., resource-specific annotation classes can be defined by owl:Restriction so that modelling effort and verbosity are reduced. These should follow the same conventions.
Usage guidelines
Resource-specific subclasses of frac concepts
As corpus-derived information requires provenance and other metadata, the frac module uses reification (class-based modelling) for concepts such as frequency or embeddings. In a data set, this information will be recurring, and for redundancy reduction, we recommend to provide resource-specific subclasses of frac concepts that provide metadata by means of owl:Restrictions that provide the value for the respective properties. This was illustrated above for the relevant frac classes.
As a rule of best practice, we recommend for such cases to provide (a copy of) the OWL definitions of resource-specific classes in the same graph (and file) as the data.
Within the graph containing the data, the following SPARQL 1.1 query must return the full frac definition of all instances of, say, :EPSDFrequency (see examples above):
CONSTRUCT {
?data a ?class, ?sourceClass; ?property ?value.
} WHERE {
?data a ?sourceClass. # e.g., [] a :EPSDFrequency
?sourceClass (rdfs:subClassOf|owl:equivalentClass)* ?class.
FILTER(strstarts(str(?class),'http://www.w3.org/ns/lemon/frac#'))
# ?class: all superclasses of ?sourceClass which are in the frac namespace
{ # return all value restrictions
?class (rdfs:subClassOf|owl:equivalentClass)* ?restriction.
?restriction a owl:Restriction.
?restriction owl:onProperty ?property.
?restriction owl:hasValue ?value.
} UNION {
# return all directly expressed values
?data ?property ?value.
FILTER(?property in (dct:source,rdf:value))
# TODO: update list of properties
}
}
This query can be used as a test for frac compliancy, and for property `inference'. Note that it does not support owl:intersection nor owl:join, nor owl:sameAs.
We use the OWL2/DL vocabulary for modelling restrictions. However, lemon is partially compatible with OWL2/DL only in that several modules use rdf:List -- which is a reserved construct in OWL2. Therefore, the primary means of accessing and manipulation lemon and ontolex-frac data is by means of SPARQL, resp., RDF- (rather than OWL-) technology. In particular, we do not guarantee nor require that OWL2/DL inferences can be used for validating or querying lemon and ontolex-frac data.
RDF Serializations and CSV
Usually, numerical information drawn from corpora is distributed and shared as comma-separated values (CSV), e.g., ngram lists or embeddings.
Ontolex-frac as an RDF vocabulary is agnostic about its serialization (RDF/TTL, RDF/XML, JSON-LD, etc.), but in particular, it is compliant with CSV and related tabular formats by means of W3C recommendations such as CSV2RDF, RDB Direct Mapping
and the RDB to RDF Mapping Language. For corpus-derived lexical-semantic information which is typically distributed in CSV, the best practice is to continue to do so, but to provide a mapping to Ontolex-frac as this provides a vocabulary for their interpretation as Linked Data, and thus establishes an interoperability layer over the raw data without creating additional overhead.
Ontolex-frac is compliant with CSV formats, but its handling of structured information has an impact on the CSV format. In particular, individual dimensions of embeddings must not use comma as separator in order to be mapped to a single literal. For the example embedding of frak above, the first column (containing the word) should be comma-separated, the following columns (containing the embedding) should be white-space separated.
Acknowledgements
TBC
References
from lexicog, to be revised
[1]
J. McCrae, G. Aguado-de Cea, P. Buitelaar, P. Cimiano, T. Declerck, A. Gómez-Pérez, J. Gracia, L. Hollink, E. Montiel-Ponsoda, D. Spohr, and T. Wunner, "Interchanging lexical resources on the Semantic Web" . Language Resources and Evaluation, vol. 46, 2012.
[2]
B. Klimek and M. Brümmer, "Enhancing lexicography with semantic language databases" Kernerman Dictionary News, 23, 5-10. 2015.
[3]
J. Gracia, M. Villegas, A. Gómez-Pérez, and N. Bel, "The apertium bilingual dictionaries on the web of data" Semantic Web Journal, vol. 9, no. 2, pp. 231-240, Jan. 2018.
[4]
J. Bosque-Gil, J. Gracia, E. Montiel-Ponsoda, and G. Aguado-de Cea, "Modelling multilingual lexicographic resources for the web of data: the k dictionaries case" in Proc. of GLOBALEX'16 workshop at LREC'15, Portoroz, Slovenia, May 2016.
[5]
F. Khan, J. E. Díaz-Vera, and M. Monachini, "Representing Polysemy and Diachronic Lexico-Semantic Data on the Semantic Web" In SWASH at ESWC (2016)
[6]
T. Declerck and E. Wandl-Vogt, "Cross-linking Austrian dialectal Dictionaries through formalized Meanings" In Proceedings of the XVI EURALEX International
Congress, pp. 329–343. 2014.
[7]
F. Abromeit, C. Chiarcos, C. Fäth and M. Ionov, "Linking the Tower of Babel: Modelling a Massive Set of Etymological Dictionaries as RDF" In LDL 2016 5th Workshop on Linked Data in Linguistics: Managing, Building and Using Linked Language Resources (p. 11). May 2016.
[8]
J. Bosque-Gil, J. Gracia, and A. Gómez-Pérez, "Linked data in lexicography" Kernerman Dictionary News, pp. 19-24, Jul. 2016.
[9]
T. Declerck, E. Wandl-Vogt, and K. Mörth, "Towards a Pan European Lexicography by Means of Linked (Open) Data" In Electronic lexicography in the 21st century: linking lexical data in the digital age. Proceedings of the eLex 2015 conference (pp. 342-355), 2015.
[10]
J. Bosque-Gil, J. Gracia, and E. Montiel-Ponsoda, "Towards a module for lexicography in OntoLex" in Proc. of the LDK workshops: OntoLex, TIAD and Challenges for Wordnets at 1st Language Data and Knowledge conference (LDK 2017), Galway, Ireland, vol. 1899. CEUR-WS, pp. 74-84, Jun 2017.
[11]
A. Parvizi, M. Kohl, M. González, R. Saurí, "Towards a Linguistic Ontology with an Emphasis on Reasoning and Knowledge Reuse" Language Resources and Evaluation Conference (LREC), May 2016.
[12]
J. Gracia, I. Kernerman, and J. Bosque-Gil, "Toward linked data-native dictionaries" in. Proc. of eLex 2017 conference (Electronic lexicography in the 21st century), in Leiden, Netherlands. Lexical Computing CZ s.r.o., pp. 550-559, Sep. 2017.
[13]
S. Stolk, "OntoLex and Onomasiological Ordering: Supporting Topical Thesauri" in Proc. of the LDK2017 Workshops, NUI Galway, Ireland, 18 June (pp. 60–67), 2017.
[14]
I. El Maarouf, J. Bradbury, and P. Hanks, "PDEV-lemon: a Linked Data implementation of the Pattern Dictionary of English Verbs based on the Lemon model". In 3rd Workshop on Linked Data in Linguistics: Multilingual Knowledge Resources and Natural Language Processing (p. 88). 2014.
[15]
F. Khan and F. Boschetti, "Towards a Representation of Citations in Linked Data Lexical Resources" In proc. of the XVIII EURALEX International Congress (EURALEX 2018). 2018
[16]
animal. American Heritage Dictionary. Houghton Mifflin Harcourt, 1994. Last accessed 28.10.18.
[17]
blanco. Diccionario de la Lengua Española (DLE). Versión electrónica de la 23. Edición. December 2017. Last accessed 28.10.18.
[18]
air. Oxford English Living Dictionaries Online. Last accessed 01.11.18. https://en.oxforddictionaries.com/definition/air


")
")
The property frequency assigns a particular ontolex:Element a frac:CorpusFrequency.